

Unternehmen produzieren im Rahmen ihrer Geschäftstätigkeit täglich riesige Datenmengen. Dabei sind qualitativ hochwertige Daten die Grundlage für Analysen und Auswertung auf allen Ebenen der Unternehmenshierarchie und kritisch für die Zielerreichung. Das konzernweite Risiko- und Versicherungsmanagement stellt dabei keine Ausnahme dar.
Was sind Ober- und Unterziele im Risk- und Insurance Management?
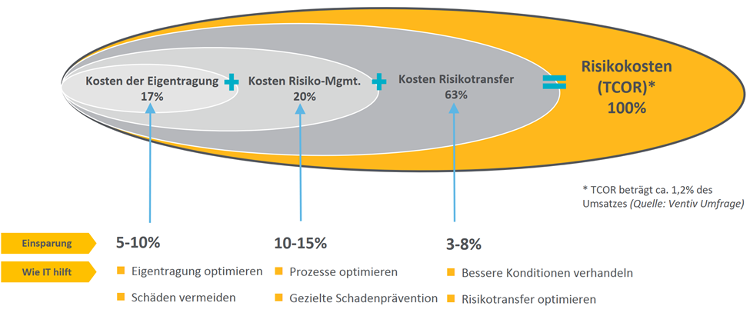
Schauen wir uns beispielhaft das klassische Oberziel „Optimierung der unternehmensweiten Kosten für versicherbare Risiken um X Prozent bis Ende 201X“ an. Diese Kennzahl (auch bekannt als „Total Cost of Insurable Risk“ /TCOiR) ist im besten Fall so definiert, dass es spezifisch, messbar, (möglichst) erreichbar und terminiert ist. Ein Oberziel kann aber nur erreicht werden, wenn eine Reihe anderer, komplementärer Unterziele erreicht wird (beim TCOiR spricht man daher von einer zusammengesetzten Kennzahl).
Im Zusammenhang mit der TCOiR-Optimierung fallen mir beispielhaft die folgenden Unterziele ein:
- Optimierung der Kosten der Schadenkontrolle: z.B. Investitionen in Brand-/Umweltschutz, Qualitätsmanagement, also Kosten, die mit der Kontrolle eines Risikos in Verbindung stehen.
- Optimierung der Kosten für selbst getragene Schäden (Retention): z.B. bewusst oder unbewusst nicht versicherte Schäden, nicht versicherbare Schäden oder Selbstbeteiligungen.
- Optimierung der Kapitalkosten: z.B. kalkulatorische Kosten für gebundenes Eigenkapital, das zur Risikofinanzierung benötigt wird.
- Optimierung der Kosten für den Risikotransfer: z.B. Versicherungsprämien, Steuern, Gebühren, etc.
- Optimierung der Kosten der Risikoadministration: z.B. Kosten für die interne und externe Administration rund um das Risiko- und Versicherungsmanagement.
Sie sehen, es gibt eine Vielzahl an Variablen und Stellschrauben, an denen man drehen kann, um das Oberziel „TCOiR-Optimierung“ zu erreichen.
Warum dieser Exkurs?
Weil die Verfügbarkeit von qualitativ hochwertigen Daten und Informationen Voraussetzung für das Erreichen der Unterziele ist, die wiederum gemeinsam zur Erreichung des Oberziels beitragen. Wobei die Datenqualität beim letzten Unterziel „Optimierung der administrativen Kosten“ keine Rolle spielt, hier geht es um die Optimierung von Prozessen, z.B. des Datenaustauschs zwischen den Parteien.
Die 7 Parameter der Datenqualität
Den Begriff „Datenqualität“ zu definieren ist nicht ganz einfach, denn was in einem Kontext (z.B. Risiko- und Versicherungsmanagement) als ausreichende Datenqualität angesehen wird, mag in einem anderen Kontext (z.B. Finanzbuchhaltung) nicht ausreichend sein. Man spricht in diesem Zusammenhang auch von „fit for purpose“: ob die Datenqualität ausreichend ist, hängt von der jeweiligen Situation ab.
Die gute Nachricht: es gibt objektive Parameter, mit deren Hilfe sich die Qualität von Daten und Informationen definieren lässt. Diese sogenannten „Data Criteria“ wurden im international anerkannten COBIT-Framework definiert. Sie sind:
- Effectiveness (Wirksamkeit): die Relevanz von Informationen für den Geschäftsprozess sowie die angemessene Bereitstellung hinsichtlich Zeit, Richtigkeit, Konsistenz und Verwendbarkeit
- Efficiency (Wirtschaftlichkeit): die Optimierung des Aufwands für die Erfassung, Verarbeitung und Bereitstellung von Information
- Confidentiality (Vertraulichkeit): behandelt den Zugang zu vertrauenswürdigen Informationen
- Integrity (Integrität): bezieht sich auf die Richtigkeit, Vollständigkeit und Aktualität von Daten
- Availability (Verfügbarkeit): bezieht sich darauf, dass aktuelle und historische Informationen für berechtigte Personen verfügbar sind
- Compliance (Compliance): die Einhaltung von Gesetzen, Regulativen und vertraglichen Vereinbarungen
- Reliability (Verlässlichkeit): bezieht sich auf die Vertrauenswürdigkeit der bereitgestellten Daten
Die Parameter verhalten sich teilweise komplementär zueinander. Sind zum Beispiel die Methoden, wie Risiko- und Versicherungsdaten erfasst werden, nicht verlässlich, dann leidet zwangsläufig auch die Datenqualität und auf dieser Basis getroffene Entscheidungen.
Datenqualität ist planbar
Für eine nachhaltig hohe Datenqualität im Risk- und Insurance Management bedarf es – wie so oft – des Zusammenspiels von Prozessen, Menschen und IT. Während sich Parameter wie „Confidentiality", „Integrity“ und „Availability“ größtenteils mit Hilfe eines geeigneten IT-Tool wie z.B. ein Risikomanagement-Informationssystems (RMIS) automatisieren lassen, bedarf es für Parameter wie „Reliability“ und „Compliance“ Bewertungen und Entscheidungen durch Menschen.
Datenqualität passiert nicht zufällig sondern muss sorgfältig geplant werden. Ein RMIS als webbasierte, zentrale Datenmanagement-Plattform ist das ideale Fundament hierfür. Denn es ermöglicht das effiziente Erfassen qualitativ hochwertiger Daten und zwar dort, wo sie anfallen: vor Ort in den Niederlassungen, bei den lokalen Risikoverantwortlichen ("Risk Ownern") , den Risk Engineers und Werksleitern. Darüber hinaus unterstützt alle am Risiko- und Versicherungsmanagement beteiligen Parteien (zentrales Risk Management, lokale Niederlassungen, Makler, Versicherer, etc.) beim Austausch relevanter Daten, Informationen, Berichte und Dokumente.
Beitragsbild: geralt auf pixabay



